Data Preprocessing for Kaggle Dataset
Jan 25, 2023
·
1 min read
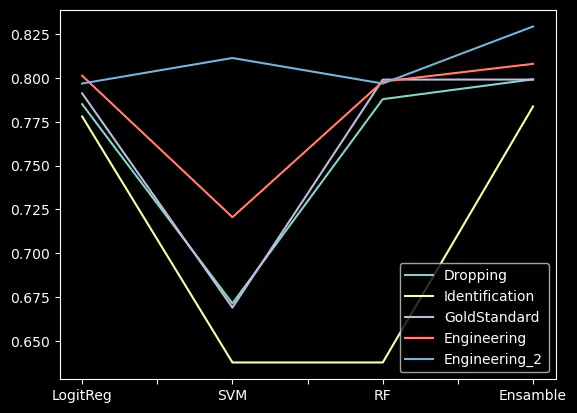
Preprocessed a Kaggle dataset, employing various data cleaning methods and feature engineering techniques. Implemented strategies like dropping NaN values, one-hot encoding, and median imputation, resulting in an average accuracy of 0.76. Enhanced features from Name and Cabin variables, leading to improved model performance, with SVM accuracy reaching 0.81. Highlighted the importance of feature engineering and effectiveness of ensemble models.