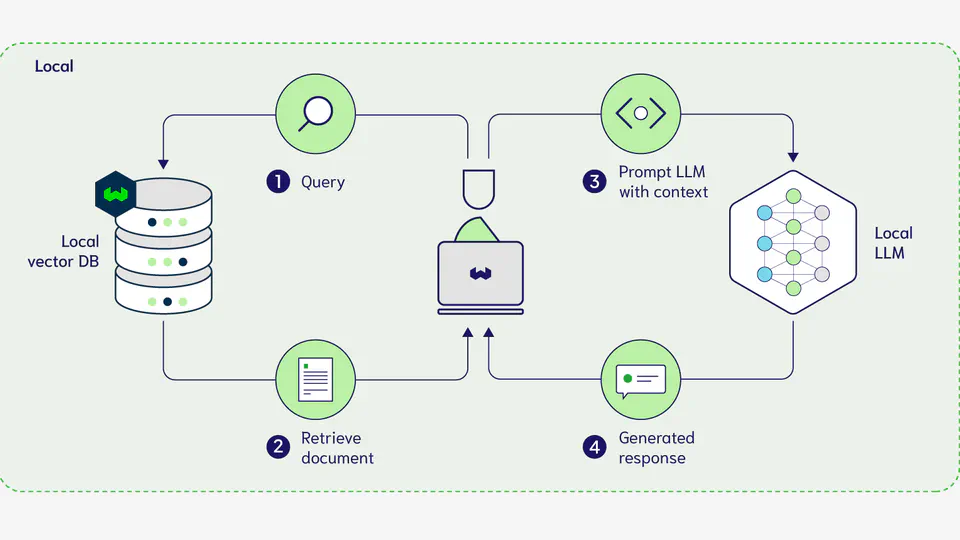
Process unstructured text data from document files efficiently, prioritizing data privacy with the implementation of locally hosted private large language models. Employed a PEFT model (LoRA) to optimize finetuning for the summarizer and classifier, yielding improved performance metrics with the help of prompt engineering and LLM reasoning.
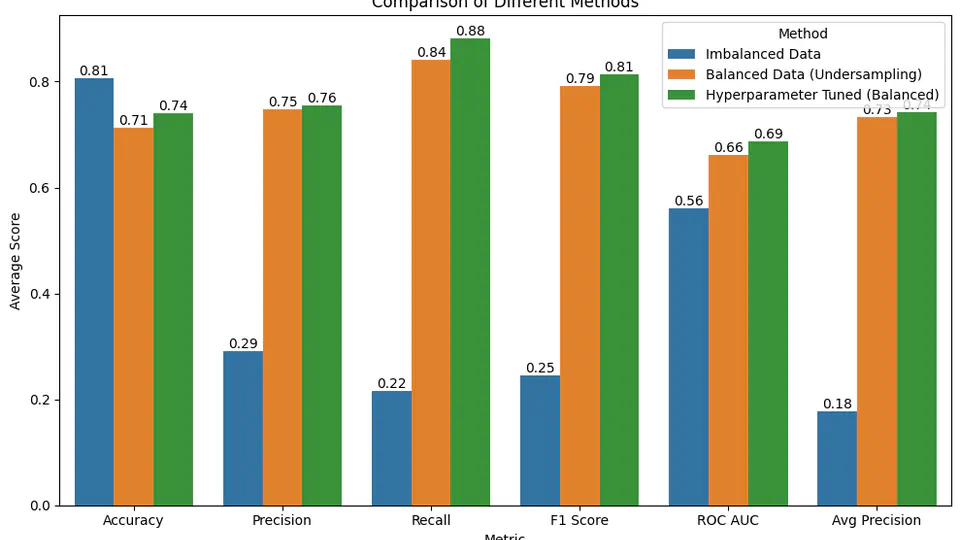
Enhance hospital decision-making in patient care by constructing a predictive model using time-series data and radiology reports to forecast intracerebral hemorrhage outcomes. The XGBoost-based model achieved an accuracy of 74.11% and precision of 75.51%, demonstrating its capacity to identify high-risk patients. Data collection was sourced from PubMed.
Explored various NLP tasks and the impact of transformer-based models on text summarization, focusing on BERT, GPT-2, and T5. Compared different summarization approaches, including DistilBART, Facebook BART, and Conversational BART, to generate effective summaries of medical reports. Addressed challenges related to input size constraints and domain-specific vocabulary.
This project is focused on addressing funding challenges for international students in US higher education. Developed a web scraping pipeline using tools such as requests, Selenium, BeautifulSoup, pandas, and re to extract extensive information on professors from CSRank rankings who are looking for new students.
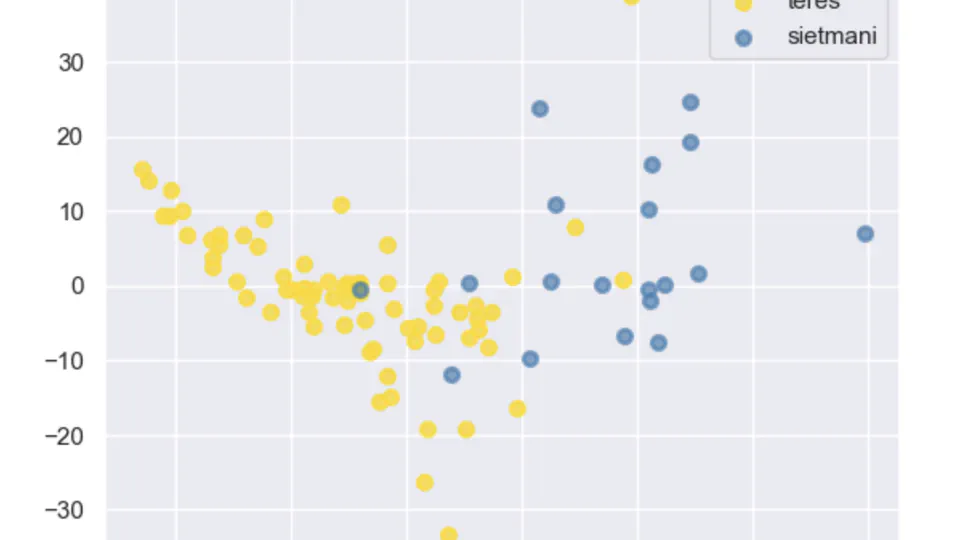
Developed a model using Support Vector Machines (SVMs) to classify two cryptic species of shellfish, achieving 97% accuracy. Explained SVM concepts and mathematical formulations, including handling complex data with slack variables and kernel tricks. Highlighted the effectiveness of SVMs in species classification without genetic analysis.