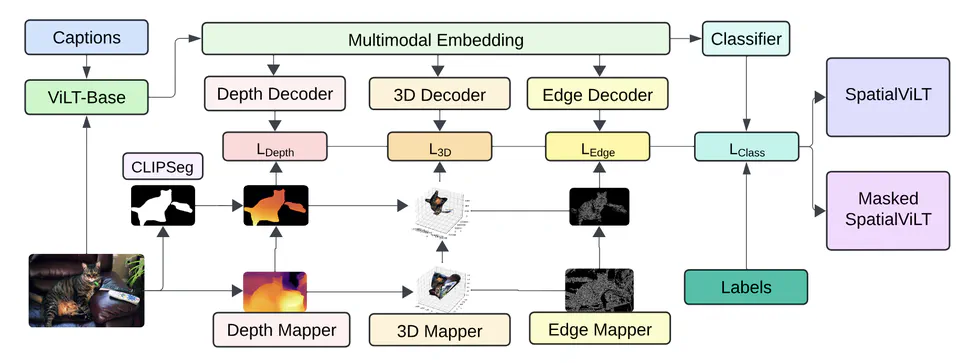
Developed a vision-language model incorporating spatial features like depth maps, 3D coordinates, and edge maps through multi-task learning, improving spatial understanding and achieving state-of-the-art results on the Visual Spatial Reasoning (VSR) dataset.
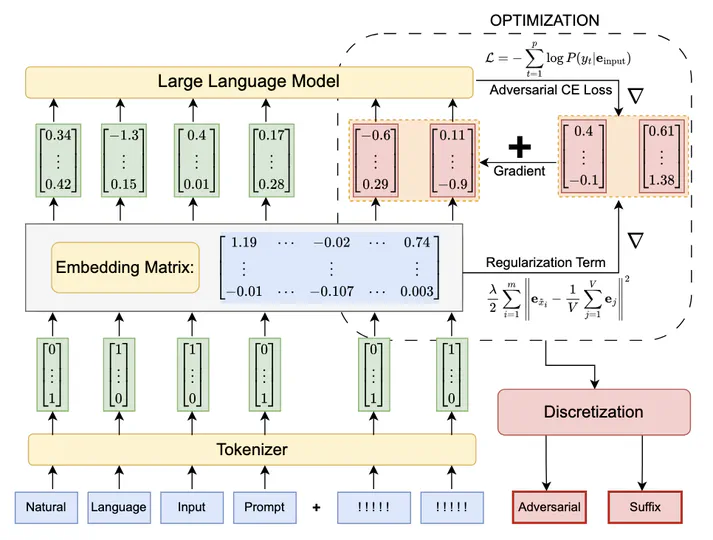
Developed a novel adversarial attack technique for Large Language Models, leveraging regularized gradients with continuous optimization to generate valid tokens and significantly improve attack efficiency and success rates
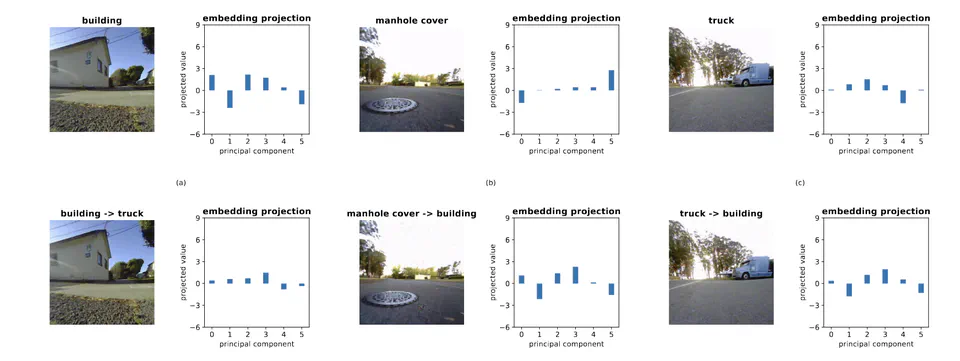
Developed a novel algorithm to adversarially modify images, exploiting the semantic representation gaps in vision-language models, enabling controlled redirection of robot navigation paths through minimal image alterations. Improved security through a detection mechanism sensitive to noise in manipulated images.
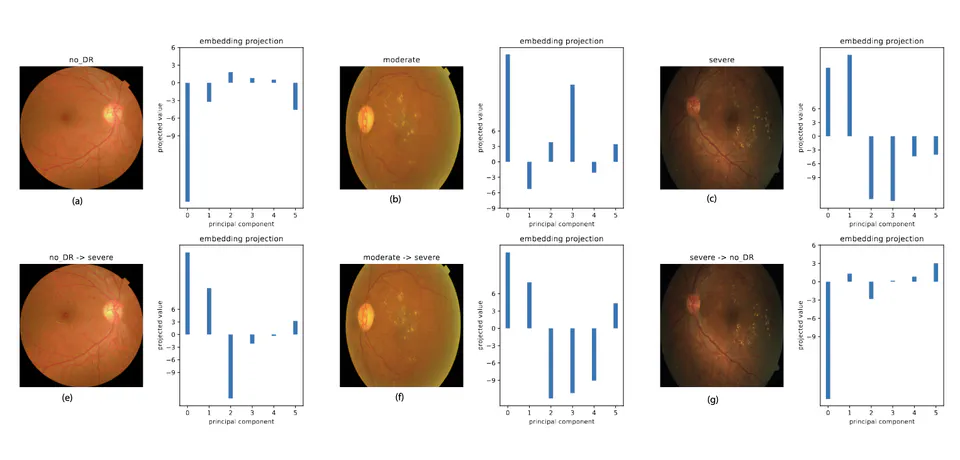
Explored vulnerabilities in vision transformers for medical image classification, demonstrating that minor modifications can significantly alter representations, and developed an efficient detection method to enhance model reliability.
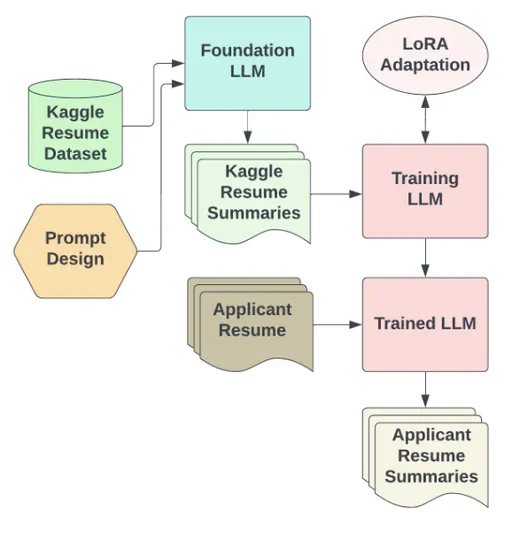
Developing text data processing pipelines with private large language models to extract meaningful features with in-context reasoning and developing fusion models to improve classification scores by combining unstructured and tabular data in multimodal settings.