Adversarial Attacks on Aligned Large Language Models
Jun 8, 2024
·
1 min read
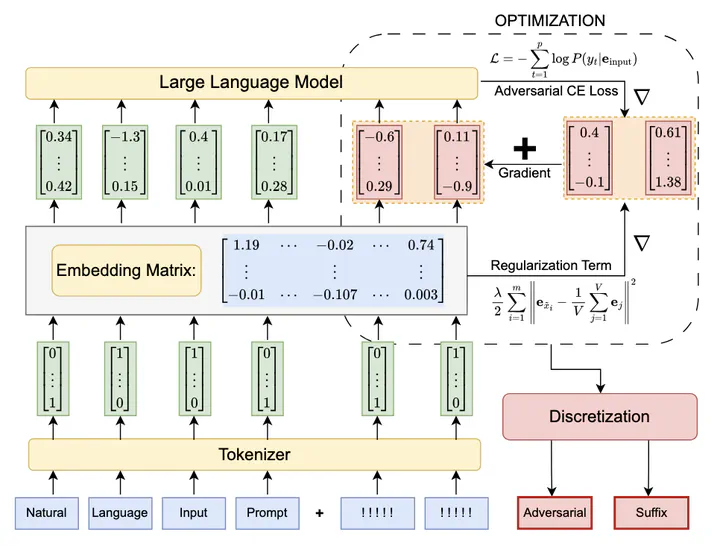
Developed a novel adversarial attack technique for Large Language Models, leveraging regularized gradients with continuous optimization to generate valid tokens and significantly improve attack efficiency and success rates