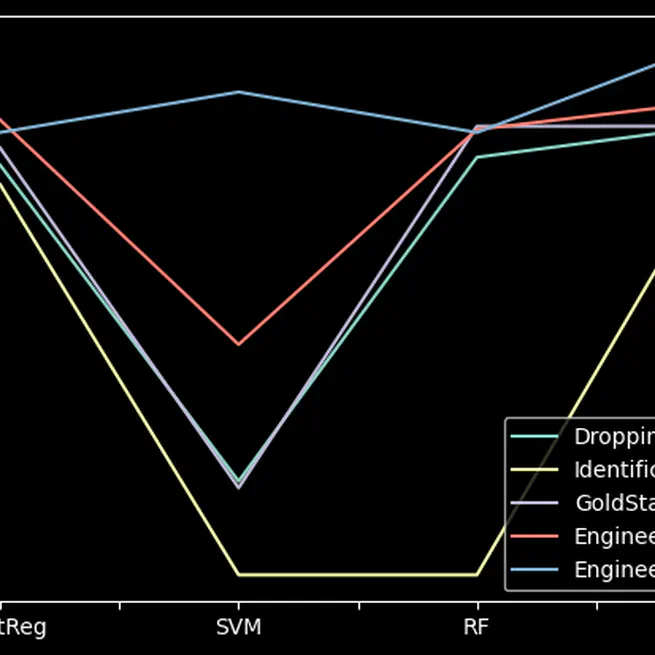
Data Preprocessing for Kaggle Dataset
Preprocessed a Kaggle dataset, employing various data cleaning methods and feature engineering techniques. Implemented strategies like dropping NaN values, one-hot encoding, and median imputation, resulting in an average accuracy of 0.76. Enhanced features from Name and Cabin variables, leading to improved model performance, with SVM accuracy reaching 0.81. Highlighted the importance of feature engineering and effectiveness of ensemble models.
Jan 25, 2023
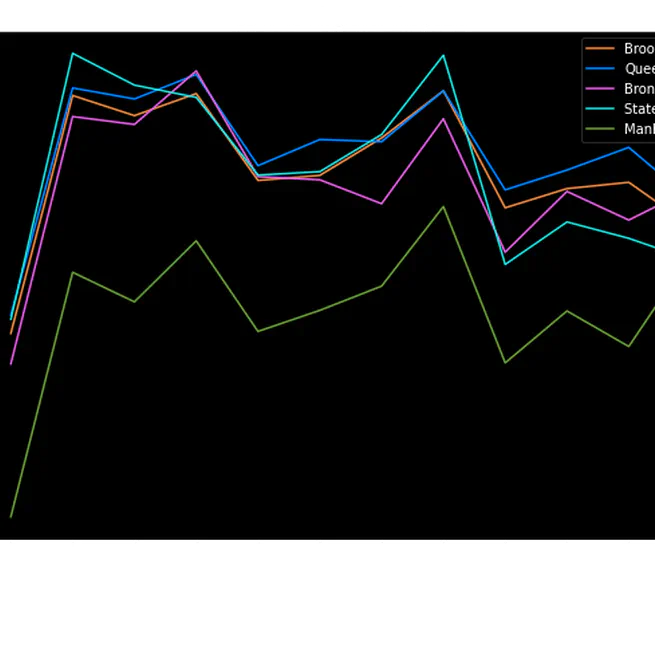
NYC Air Quality Data Analysis
Analyzed NYC air quality data focusing on pollutants like Nitrogen dioxide, Sulfur dioxide, Ozone, and PM2.5. Demonstrated a positive trend in air quality improvement over the past decade, with significant reductions in Nitrogen dioxide and PM2.5 emissions. Employed data visualization techniques to highlight the impact of emission norms and regulations, and emphasized the importance of maintaining good air quality and continuing pollution reduction efforts.
Jan 10, 2023