Multimodal Classification with LLMs - Unstructured Text Feature Extraction
Developing text data processing pipelines with private large language models to extract meaningful features with in-context reasoning and developing fusion models to improve classification scores by combining unstructured and tabular data in multimodal settings.
Aug 14, 2023
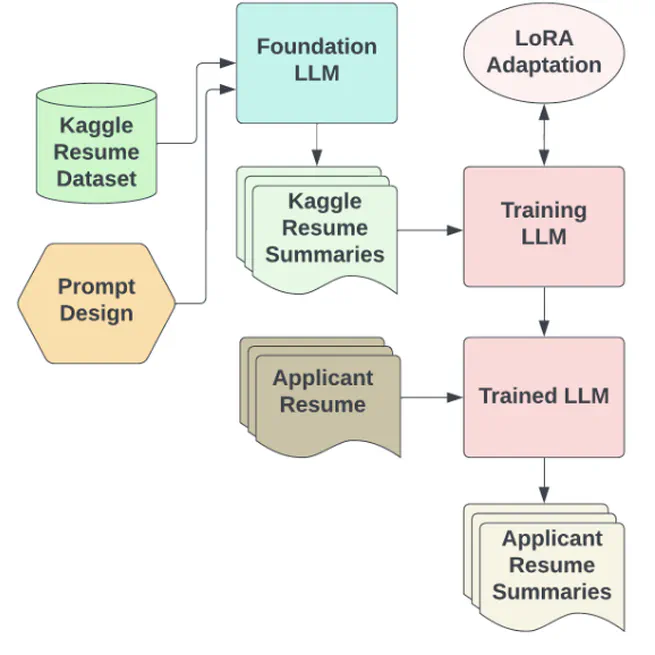
Deciphering Poorly Formatted Text using Private LLM
Process unstructured text data from document files efficiently, prioritizing data privacy with the implementation of locally hosted private large language models. Employed a PEFT model (LoRA) to optimize finetuning for the summarizer and classifier, yielding improved performance metrics with the help of prompt engineering and LLM reasoning.
Apr 25, 2023