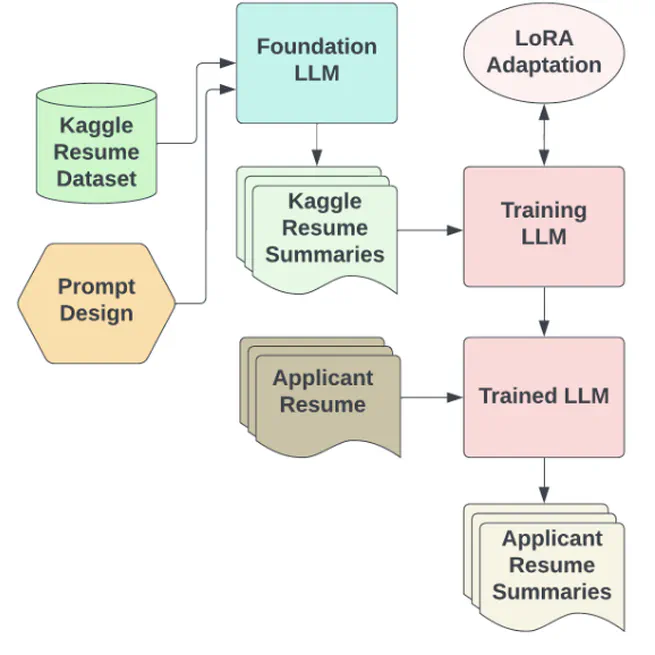
Multimodal Classification with LLMs - Unstructured Text Feature Extraction
Developing text data processing pipelines with private large language models to extract meaningful features with in-context reasoning and developing fusion models to improve classification scores by combining unstructured and tabular data in multimodal settings.
Aug 14, 2023
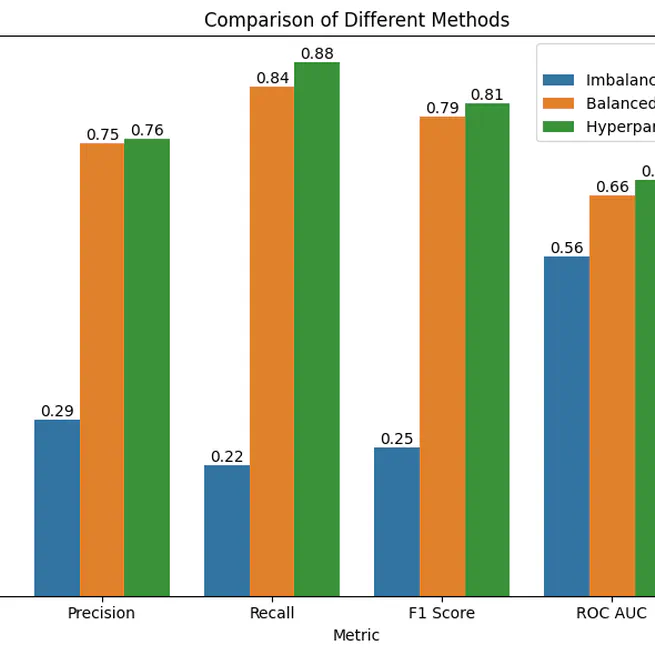
Patient Severity Prediction - Mutlivariate Time Series Data
Enhance hospital decision-making in patient care by constructing a predictive model using time-series data and radiology reports to forecast intracerebral hemorrhage outcomes. The XGBoost-based model achieved an accuracy of 74.11% and precision of 75.51%, demonstrating its capacity to identify high-risk patients. Data collection was sourced from PubMed.
Apr 20, 2023
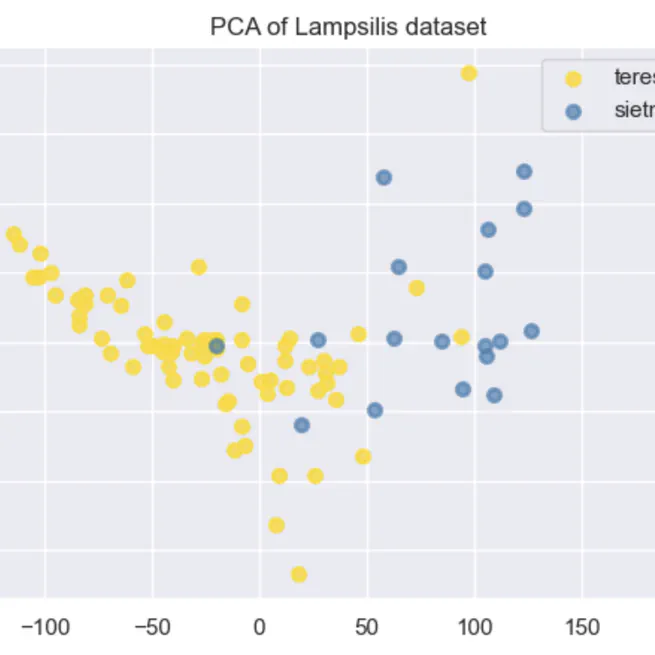
Cryptic Species Classification Using SVM
Developed a model using Support Vector Machines (SVMs) to classify two cryptic species of shellfish, achieving 97% accuracy. Explained SVM concepts and mathematical formulations, including handling complex data with slack variables and kernel tricks. Highlighted the effectiveness of SVMs in species classification without genetic analysis.
Mar 10, 2023
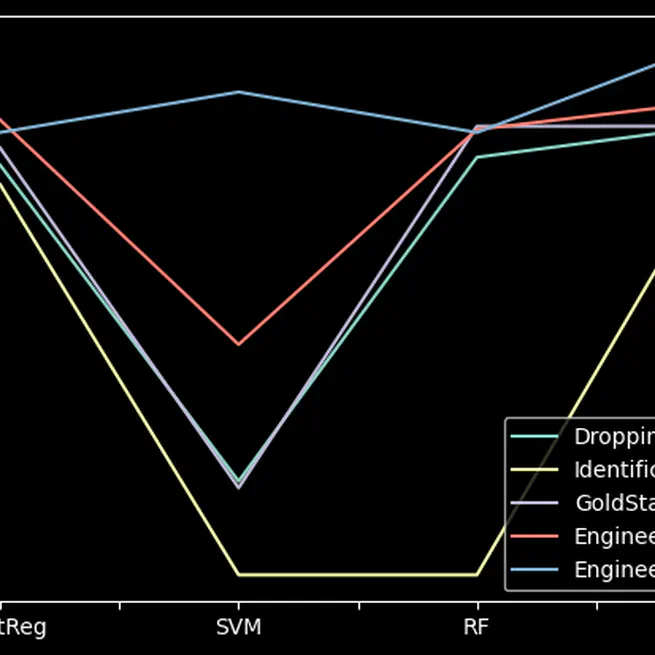
Data Preprocessing for Kaggle Dataset
Preprocessed a Kaggle dataset, employing various data cleaning methods and feature engineering techniques. Implemented strategies like dropping NaN values, one-hot encoding, and median imputation, resulting in an average accuracy of 0.76. Enhanced features from Name and Cabin variables, leading to improved model performance, with SVM accuracy reaching 0.81. Highlighted the importance of feature engineering and effectiveness of ensemble models.
Jan 25, 2023